设计模式笔记(1) -- 设计模式初探,策略模式
24 Dec 2017为了提高自己屎一样的代码能力,写出一个易于管理,便于修改的程序,最近开始接触程序的设计模式。以下权当阅读时的笔记及想法。
相信有很多人接触程序语言是从C语言开始的。当我们转向更强大的面向对象的语言,诸如C++,Java时,肯定有很多人抱有和当初的我一样的疑问:我们为什么要面向对象?Class到底有什么用,明明不已经有了类似功能的struct了为什么我们还需要额外再多一种类别?一般书中会告诉我们面向对象的四大特征:抽象,继承,多态和封装。在我看来,四大特征中抽象是目的,继承和多态则是实现抽象的手段,封装则是用来维护抽象,防止别人乱搞导致系统崩盘。经过这样,问题变成了:为什么要抽像?对于这个问题,其实答案并不高达上,原因就是懒,就是为了少写些代码,减少工作量。无论是面向对象,还是设计模式,他们所作的事情都是一个:
将应用中不需要的变化的代码混在一起,将应用中可能需要变化的代码独立出来,减少功能重复,相似的代码,做出一个易维护,可拓展,富有弹性的系统。
这个其实也是设计模式的 第一个原则。
可能有反应机灵的人就要发问了,你扯这条原则有什么用,它和减少工作量有什么关系?下面就通过一个案例来说明。
分开改变和不变
做实验物理分析,做图是免不了的,在高能物理,一般使用ROOT,一个基于C++的分析框架来分析做图。一个典型的画一维直方图的做图脚本一般如下所示
#include <TH1.h>
#include ...
void draw(const std::string name){
SetAtlasStyle();
TCanvas *canvas = new TCanvas("canvas","canvas",0,0,1000,800);
TPad* upperPad = new TPad("upperPad", "upperPad", .001, .25, .995, .995);
TPad* lowerPad = new TPad("lowerPad", "lowerPad", .001, .001, .995, .25);
upperPad->...
lowerpad->...
TFile* f1 = new TFile("path/to/file/file1Name");
TFile* f2 = new TFile("path/to/file/file2Name");
...
TH1F* hist1 = (TH1F*)f1->Get(name.c_str());
TH1F* hist2 = (TH1F*)f2->Get(name.c_str());
...
hist1->Sumw2();
hist2->Sumw2();
...
//Rebin all hist
hist1->Rebin(10);
hist2->Rebin(10);
...
//一些处理步骤
...
upperPad->cd();
hist1->Draw();
hist1->SetLineColor(2);
hist1->SetFillColor(2);
hist1->SetLineStyle(2);
hist1->SetMarkerColor(2);
hist1->SetMarkerStyle(1);
//其他hist,做类似hist1的事
...
lowerpad->cd();
//similiar process as upperpad
hist1->Draw();
hist1->SetLineColor(2);
...
...
//其他绘图步骤
...
//保存
canvas->SaveAs(name.c_str());
}
通过上述代码,我们可以看到,对于每个histgram,都要先获得文件,然后都要做一些诸如’设置二项式方差’,’合并方块’等步骤,然后再设置每个hist的样式颜色等,一般在画图中,所有hist的样式都一样,不同的只有颜色。最后画完再把它们保存。
好的,画图脚本大功告成,你通过这个脚本给老版交上了你的杰作,然而老板对这幅图有点不满意:”hist1的颜色太淡了,把它弄深点吧。”。小问题,你迅速找到相应代码行,改了颜色,又交上去。老板看了看,又说:”线还是画成虚线吧,信号分布我们一般用虚线。”这次你所要面对的是所有hist的’SetLineStyle()’代码,而且上下两个画板都得改。没办法,你只能一个一个敲,期间还得检查哪里忘敲或者敲错了。所幸万事大吉,最终图全做出来了,老板最终满意。然而下次组会时,大家讨论又提出了这样的观点:”可不可以加个新的一组信号参照点?由于我们也不知道新的效果如何,所以我们还得和旧的参照点做个比较。对了,由于加了新的点,原来的颜色选择可能不大好了,也重新改下吧”。突然,你会发现你一下子要加很多东西!诸如’TFile’,’TH1F*‘之流的代码,更糟的是,对于每个hist,这些步骤你都得重来一次!而且在改颜色时,你还得费心在茫茫代码海中去定位哪个hist的颜色设置在哪!虽然这都是不花时间的小事,但众多不花时间的事加起来,也会浪费你巨大的时间。
看到这里,可能有人就会问:”为什么你们在写程序时不先提前开个会,什么该怎么做,怎么来都决定好,之后再写程序呢?看看现在这样多浪费时间!”实际上,这样的道理大家都懂,类似这种会是会开的,但这种会只能缓解问题,并不能在实质上解决问题,主要原因有两点:
- 会议时间有限,而且人的思维总有盲点,所以不可能在一次会议中就做到对需求,实现面面俱到的分析。
- 需求会随着实现的进展而逐渐明朗化,有时随着一些结果的得出,需求可能还会发生一些变化。就像上面的例子,在做出结果后提出再看看其他信号点的分布。
所以,’需求更改,改写代码’这种事在编程中时时刻刻都有发生。而在上例中,一个’所见即所得,随着思路线性处理问题’的hard coding模式对需求更改的应对极差,其最大的原因就是充满着重复代码。这样的重复代码造成了每增加或删除一个相似步骤,我们都得对每个对象都处理一下,而增加或删除一个新对象,都要把步骤重新敲一边。这时候设计模式的第一个原则就起作用了:将不变的部分和变化的部分分开。对于上面的代码,由于每个hist处理过程都相似,且分为了三个部分,所以就采用3个函数来处理,并把变化的部分提出,作为函数的参数(为什么3个函数而不是一个函数?因为在设计函数时,要求,高内聚,低耦合,功能单一。这样在面对更改时,我们只需要更改小函数,有利于快速定位,而且小函数更加灵活且不易出错,在面对bug时调试也更加方便)。这样,上面的代码变成了这样子
#include <TH1.h>
#include ...
TH1F* GetHist(std::string name, std::string fileName, int rebinNum);
void DrawUpHist(TH1F* hist,int Color);
void DrawUpHist(TH1F* hist,int Color);
//全局变量定义,由于小脚本所以可以比较随意的定义全局变量
std::string path = "path/to/file";
std::string file1Name = "file1name";
std::string file2Name = "file2name";
...
int rebinNum = 10;
int lineS = 2;
int markerS = 1;
enum{
Color1=30,
Color2=41,
...
};
//主函数入口
void draw(const std::string name){
SetAtlasStyle();
TCanvas *canvas = new TCanvas("canvas","canvas",0,0,1000,800);
TPad* upperPad = new TPad("upperPad", "upperPad", .001, .25, .995, .995);
TPad* lowerPad = new TPad("lowerPad", "lowerPad", .001, .001, .995, .25);
upperPad->...
lowerpad->...
hist1 = GetHist(name,file1Name,rebinNum);
...
upperPad->cd();
DrawUpHist(hist1,Color1);
...
lowerpad->cd();
DrawLowHist(hist1,Color1);
...
//其他绘图步骤
...
//保存
canvas->SaveAs(name.c_str());
}
TH1F* GetHist(std::string name, std::string fileName, int rebinNum){
TFile* f = new TFile((path+fileName).c_str());
TH1F* hist = (TH1F*)f->Get(name.c_str());
hist->Sumw2();
hist->Rebin(rebinNum);
//一些处理步骤
...
}
void DrawUpHist(TH1F* hist,int Color){
hist->Draw();
hist->SetLineColor(Color);
hist->SetFillColor(Color);
hist->SetLineStyle(lineS);
hist->SetMarkerColor(Color);
hist->SetMarkerStyle(markerS);
}
void DrawUpHist(TH1F* hist,int Color){
//similiar process as upperpad
...
}
在上面代码中使用了大量的全局变量,其实有很多都并不是必须的,完全可以把他们放入函数中。这么做的考虑是由于是单一文件小脚本,全局变量的缺点基本被掩盖,而通过这样可以把所有可能需要改变的量集中在了一起,每当需求做出改变时也可以迅速的定位位置提高工作效率。有时甚至可以将相似改变写成一行,然后使用sed之流的进行快速批量替换。
回到一开始的问题,面向对象中抽象是在做什么?就是把一类事物中相似的地方提取出来,制作一个新的概念。而对于不同的部分,则通过继承来加以实现。可以说,函数是对单一流程代码分类集中的产物,而类则是对变量函数分类集中的产物。这也给了我们关于”什么时候该面向对象”问题的解答:当工程已经大到需要将函数等分类处理的时候,就需要面向对象了。
继承与多态
在面向对象中,超类负责公共部分,子类负责不同部分,这样是否就可以万事大吉,高枕无忧了呢?遗憾的是不会,否则也就没有设计模式什么事了。首先,我们看一下某个案例的疑难。
某公司设计了个关于鸭子的小游戏,里面有绿头鸭,斑头鸭等等。但问题来了,有的鸭子会飞,有的鸭子不会飞。如果我们认为飞不是所有鸭子的共同点而不应用到超类,那么我们需要为绝大多数会飞的鸭子子类每个写一个飞的函数!如果我们认为绝大多数鸭子会飞而把飞写到超类里。那么每拓展一个鸭子子类,我们都需要考虑它会不会飞,是否用一个空的飞函数来覆盖父类方法。
更糟糕的事情来了,因为这是个游戏,所以还会有一些和玩家的互动,比如玩家撒网捕获鸭子后,鸭子的飞行就需要改变。不同种类,年龄的鸭子飞行能力均有所差异。很难将他们统一写到一个超类中。而写到子类中则会造成重复代码的灾难
通过这段分析,我们已经意识到,”飞行”这种经常会动态变化的行为就不应该在鸭子类中,由设计模式第一条原则,我们应该将其抽出来另建一类,比如flyBehavior。对于Java,由于只允许单一继承,所以”飞行”只能建成一个接口。而对于C++,下面的分析将会表明其最好也是建成和Java接口功能相似的东西-虚基类。
好的,我们已经把飞行独立出来了。如果还有其他易于改变的行为,如叫声,我们也按照原则把它们独立出来。现在我们考虑如何再把它们加到鸭子的子类中。先以Java为例,在Java中,接口不能有任何定义,所以如果每个类都直接继承接口,那么所做的事和直接在鸭子子类中写飞函数一模一样!所以肯定不能这么干。那么该怎么做呢?设计模式的第二条原则就是为了解决此而诞生的:
针对接口(超类)编程,而不是针对实现编程
这条原则的实现手段则是面向对象的多态。
在上面,无论是直接继承飞行,还是独立飞行直接实现接口,它们都是直接应用实现到子类中,这种做法使得虽然实现与母类分离,但却和子类绑的死死的,矛盾仅仅是被转移,而不是消减,子类的行为仍然僵硬。要摆脱这样,我们将具体的飞行行为继承飞行这个接口,示例图如下,然后让子类只与FlyBehavior这个抽象接口来沟通。那么如何沟通呢?这时候就轮到多态大显神威的时候了。
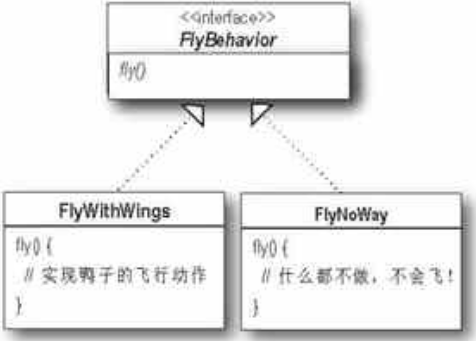 可能有的朋友不懂什么是多态,那么首先我介绍一下什么是多态,当我们针对实现编程时,最常用的实例语句是
可能有的朋友不懂什么是多态,那么首先我介绍一下什么是多态,当我们针对实现编程时,最常用的实例语句是
Duck duckA;
duckA = new Duck();
duckA.makeSound();
...
而应用多态后,实例语句变为
Animal animalA;
animalA= new Duck();
animalA.makeSound();
...
在代码上看,二者区别仅在于声明的变量类型不同。但在运行时,编译器会把子类的与父类相同名称的行为赋予父类,也就是说animalA.makeSound()执行的是Duck类的makeSound(),而不是父类Animal的!这样,其他地方的调用就可以做到”声明类时根本不用理会将来执行时真正的对象类型,将来用到时再动态绑定”。更棒的是,如果你哪天不想要Duck这个绑定了,你可以用语句animalA= new Dog();重新再绑一个,此时animalA的行为就完全是狗而非鸭子了!这也是针对超类编程相对针对实现编程的一大优点。
现在我们也可以解答为什么对于c++,超类最好是虚基类。因为在多态中,我们希望的是父类实现子类的行为,而父类可实例化的话,在一群动态绑定子类中偶尔突然绑回父类显得有些突兀,直接绑定父类可能会给人留下”我不是用它来做多态”的印象,给读代码的人造成困扰。
策略模式
现在我们来运用多态,在Duck类中加入飞行接口的声明,然后加入两个函数setFlyBehavior()和performFly()
public class Duck{
FlyBehavior flyBehavior;
//...
public Duck(){}
public void setFlyBehavior(FlyBehavior flyBehavior){
this.flyBehavior = flyBehavior;
}
public void performFly(){
flyBehavior.fly();
}
}
在构造子类时,我们可以重写构造函数达到设定默认飞行的模式。如果游戏运行时飞行条件发生了改变,我们也可以使用原本父类的函数setFlyBehavior()达到动态改变飞行的模式。
public class RedHeadDuck extends Duck{
public RedHeadDuck(){
flyBehavior = new FlyWithWings();
}
...
}
这样整个鸭子的体系就是如下图所示,在设计模式中,”行为”一般成为”算法”,即鸭子能做的事。
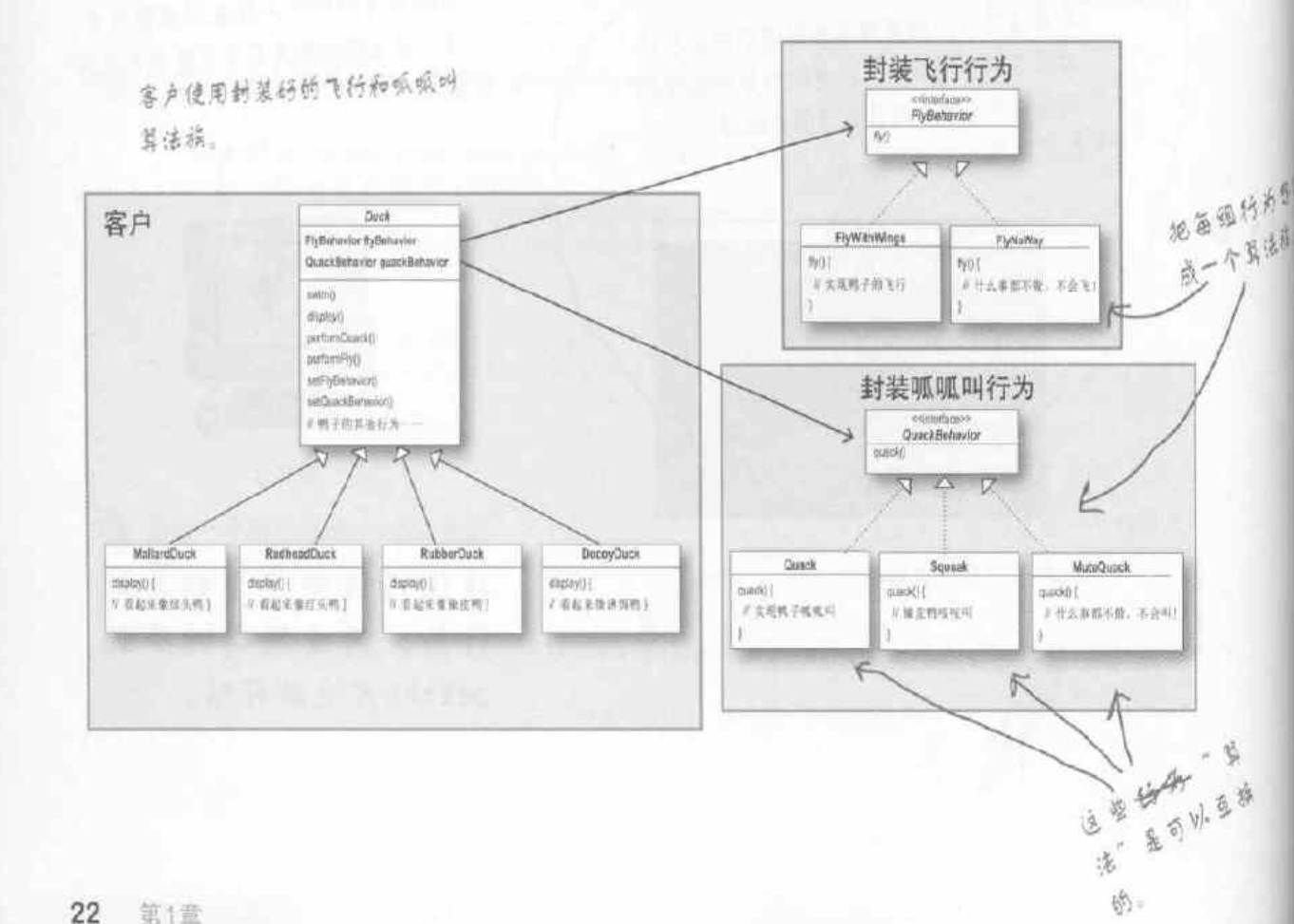
在此例中,我们发现这种运用多态的方式两个类的耦合并不是依靠继承,而是靠和适当的行为对象”组合”而来。这是一个很重要的技巧,也是设计模式的第三个原则
多用组合,少用继承
使用组合建立的系统拥有很大的弹性,不仅可以将算法封装成类,更可以在运行时根据需要动态的改变行为,只要组合的行为对象符合正确的接口标准。
在此例中,我们将鸭子的各个算法独立封装起来,并通过多态是他们可以相互替换。这种模式被称为策略模式,它的详细定义如下:
策略模式定义了算法族,分别封装起来,让他们可以互相替换,此模式让算法的变化独立于使用算法的客户。
总结
- 为什么要面向对象? 当系统足够大时,函数的分类处理已经不能再减少重复代码。为了进一步减少功能类似,代码冗余,制作出一个易维护,可拓展,富有弹性的系统,我们需要将它们进一步分类,抽象。
- 面向对象的四大特征:抽象,继承,多态,封装
-
设计模式的三个原则(目前,以后还会有更多)
1.将应用中不需要的变化的代码混在一起,将应用中可能需要变化的代码独立出来,减少功能重复,相似的代码。
2.针对接口(超类)编程,而不是针对实现编程
3.多用组合,少用继承
- 策略模式:此模式定义了算法族,分别封装起来,让他们可以互相替换,此模式让算法的变化独立于使用算法的客户